已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
”人工智能 自然语言处理 维基百科 语料库“ 的搜索结果
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
经过1、英文小写.2、词干提取.3、词形还原.4、分词.5、去停用词
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
已经做了 1、分词 2、去停用词 3、英文小写 4、词干提取 5、词形还原
直接下载下来的维基百科语料是一个带有html和markdown标记的文本压缩包,基本不能直接使用。目前主流的开源处理工具主要有两个:1、Wikipedia Extractor;2、gensim的wikicorpus库。 然而,这两个主流的处理方法都不...
NLP语料库
自然语言处理(NLP)是计算机科学与人工智能领域的一个分支,旨在让计算机理解、处理和生成人类语言。在NLP任务中,语料库和数据预处理是非常重要的部分,它们为模型提供了训练和测试的数据来源。本文将深入探讨自然...

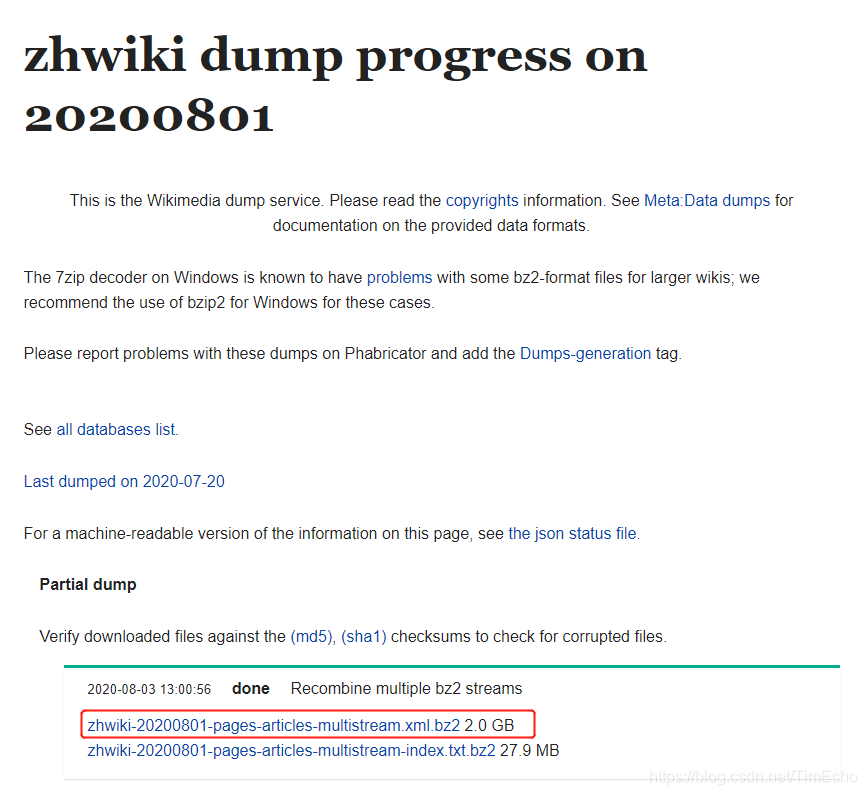
本篇文章主要介绍如何通过中文维基百科语料库来训练一个word2vec模型。 相关资料下载: 中文维基百科下载地址:https://dumps.wikimedia.org/zhwiki/20180720/ WikiExtractor项目git地址:...

本篇主要介绍如何通过中文维基百科语料库来训练一个word2vec模型。相关资料下载:一、语料库的下载我下载是20190401文件,1.5G左右是一个压缩包,下载的时候需要注意文件的名称。二、语料库文章的提取下载完成之后...
自然语言处理是机器学习和人工智能的一个迷人领域。这篇博客文章启动了一个具体的 NLP 项目,涉及使用维基百科文章进行聚类、分类和知识提取。灵感和一般方法源自《Applied Text Analysis with Python》一书。
转自:https://blog.csdn.net/sinat_29957455/article/details/81432846 ...

训练结束后会产生三个模型文件wiki_zh.model、wiki_zh.model.wv.vectors.npy、wiki_zh.model.syn1neg.npy,找到其中的:opencc-1.0.1-win64,将wiki_zh.txt拷贝到该文件夹下,在opencc-1.0.1-win64文件夹下使用如下...
探秘MITIE中文维基语料库:自然语言处理的新里程碑 项目地址:https://gitcode.com/howl-anderson/MITIE_Chinese_Wikipedia_corpus 在人工智能的领域中,自然语言处理(NLP)是至关重要的一环,而高质量的数据集则是...
中文维基百科语料库 + word2vec 训练中文模型 1.准备数据 训练中文模型,中文预料数据是必须的,可以使用中文的维基百科,也可以是搜狗的新闻语料库。 中文维基百科地址:...
2021年2月26日收到2021年7月6日修订2021年7月29日接受在线预订2021年保留字:词义消歧(WSD)WordNet词典维基百科语料库基于知识的无监督和监督系统Senseval和SemEval数据集A B S T R A C T词义消歧(WSD)是根据


本篇主要介绍如何通过中文维基百科语料库来训练一个word2vec模型。 相关资料下载: 中文维基百科下载地址:https://dumps.wikimedia.org/zhwiki/ WikiExtractor项目git地址:...
自然语言处理是一种涉及计算机对自然语言进行处理和...大语言模型的目标是构建一个通用的、具有智能的自然语言处理系统,能够在多种任务和语言上表现出色。NLP(自然语言处理)和LLM(大语言模型)是相关但不同的概念。
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地